I have always been fascinated by the way analogies can be found between biology and the most -seemingly- irrelevant topics. In the past I have worked on linguistic analogies of the genomic texts (see examples here and here) and we have also been particularly interested in drawing analogies for genomes as self-organising entities (see for instance this nice paper).
In our group, one of our most active interest is the evolution of genome architecture in an almost literal sense of the term. Thus we try to envision the genomes, especially those of eukaryotes, as structures with an inherent organization, which we cannot (obviously) yet fully decipher. In this respect, we have been studying genomic characteristics for which we can get a lot of data, such as gene expression, regulation, chromatin structure, conservation etc under the lens of their spatial distribution in the genome in both linear and three-dimensional space.
So earlier this year, starting from an already published dataset, on which we had worked before, we tried to answer a simple question: Do genes with similar properties cluster in the linear space of eukaryotic genomes? This is obviously not a new question. In fact since the very first gene expression analysis papers, people had already realized that gene expression is correlated with gene position (see for example here and here). Soon after came analyses that showed that the proximity between genes was also associated with common regulation (like e.g. in this great paper). In our work we tried to combine all of the above studied properties, plus some more, to show that genes in a simple eukaryotic genome like yeast tend to cluster in particular domains with clear structural and organizational characteristics. Your can read more in our paper here and two relevant blog posts here and there, but the main point is that the yeast genome looks to have involved in such a way, so that their is a "division of labour" of genes in distinct neigbourhoods of the genome, the clearest of which is a distinction between the edges and the centers (i.e. the centromeres) of the chromosomes.
In our group, one of our most active interest is the evolution of genome architecture in an almost literal sense of the term. Thus we try to envision the genomes, especially those of eukaryotes, as structures with an inherent organization, which we cannot (obviously) yet fully decipher. In this respect, we have been studying genomic characteristics for which we can get a lot of data, such as gene expression, regulation, chromatin structure, conservation etc under the lens of their spatial distribution in the genome in both linear and three-dimensional space.
So earlier this year, starting from an already published dataset, on which we had worked before, we tried to answer a simple question: Do genes with similar properties cluster in the linear space of eukaryotic genomes? This is obviously not a new question. In fact since the very first gene expression analysis papers, people had already realized that gene expression is correlated with gene position (see for example here and here). Soon after came analyses that showed that the proximity between genes was also associated with common regulation (like e.g. in this great paper). In our work we tried to combine all of the above studied properties, plus some more, to show that genes in a simple eukaryotic genome like yeast tend to cluster in particular domains with clear structural and organizational characteristics. Your can read more in our paper here and two relevant blog posts here and there, but the main point is that the yeast genome looks to have involved in such a way, so that their is a "division of labour" of genes in distinct neigbourhoods of the genome, the clearest of which is a distinction between the edges and the centers (i.e. the centromeres) of the chromosomes.
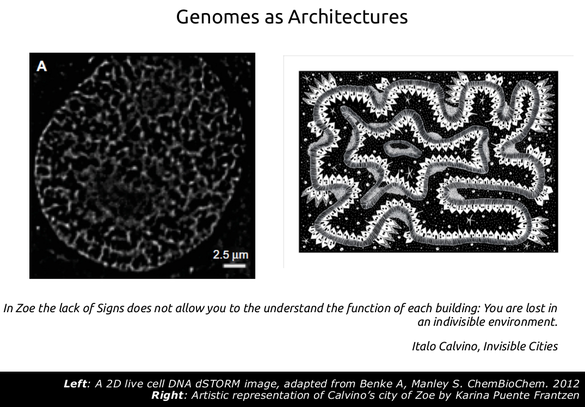
This work lead to some immediate follow-up questions. Thus, we were able to show that genes, located close to the centromeres tend to be more conserved that the genome average, or that genes located away from the centromeres tend to be spaced with longer intergenic regions inbetween, but a more direct question would be to define some more detailed aspects of these domains in terms of macroscopic properties discernible by cellular machinery. Using another urbanistic analogy, one could wonder how these "gene neighborhoods looked like". Imagine flying above a city that you don't know very well. If the city has been planned in a way that everything is homogeneous you would not be able to say much about the basic landmarks of the city. This holds true for a certain type of urban landscapes called "utopic". These are not in the sense of "earthly paradises" but in the literal sense of the term ("ου τόπος" which is greek for "no place"), meaning that there is a lack of landmarks exactly because of the fact that they have been ultra-planned to lack any such point of reference. Everything is similar to each other and this overall homogeneity is supposed to enforce equality of access and maximal sharing of space.
Back in the 20s and 30s these concepts were highly popular as can be seen in Le Corbusier's Ville Radieuse which was the inspiration for Oscar Niemeyer planning of the city of Brazilia. Utopian architecture has also inspired Italo Calvino, who in one of his Invisible Cities describes the city of Zoe as a place where "the lack of signs does not allow you to understand the function of each building; your are lost in an indivisible environment". The Ville Radieuse (shown below) or an artistic representation of Zoe (above right) are examples of how the lack of landmarks may appear at the same time all-encompassing but also hard to navigate. In fact, utopian architectures are nowadays only used in particular cases such as airport terminals or metro stations, which you can only navigate when assisted by additional signals (gate numbers, names of stations) and very often the constant help of the voice of an announcer. Most modern city landscapes are not like this. They have particular landmarks: parks, boulevards, avenues and buildings that are distinct from each other, which gives them a symbolic character. They are not designed to be thus but have probably "evolved" (in a relaxed sense of the term) like this through the gradual aggregation of elements. They are in this sense easier to "parse" by being able to distinguish the City Hall from the General Hospital, the University campus from an industrial zone etc.
Back in the 20s and 30s these concepts were highly popular as can be seen in Le Corbusier's Ville Radieuse which was the inspiration for Oscar Niemeyer planning of the city of Brazilia. Utopian architecture has also inspired Italo Calvino, who in one of his Invisible Cities describes the city of Zoe as a place where "the lack of signs does not allow you to understand the function of each building; your are lost in an indivisible environment". The Ville Radieuse (shown below) or an artistic representation of Zoe (above right) are examples of how the lack of landmarks may appear at the same time all-encompassing but also hard to navigate. In fact, utopian architectures are nowadays only used in particular cases such as airport terminals or metro stations, which you can only navigate when assisted by additional signals (gate numbers, names of stations) and very often the constant help of the voice of an announcer. Most modern city landscapes are not like this. They have particular landmarks: parks, boulevards, avenues and buildings that are distinct from each other, which gives them a symbolic character. They are not designed to be thus but have probably "evolved" (in a relaxed sense of the term) like this through the gradual aggregation of elements. They are in this sense easier to "parse" by being able to distinguish the City Hall from the General Hospital, the University campus from an industrial zone etc.

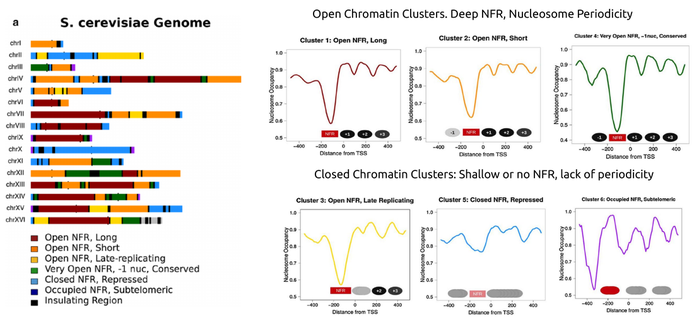
But what is the case for the genomes of eukaryotes? Do they look like uniform Utopias or are they embedded with particular landscapes? To answer this question we set out to define one set of possible landmarks in the genome of S. cerevisiae by looking into a particular class of genomic "neighborhoods". Starting from a recent observation of topologically associated domain in yeast (see here) we split the genome in such domains that are expected to be structurally self-contained, (that is they tend to have much more physical interactions within them than inbetween) and then looked into one particular chromatin property. After splitting the yeast genome in topologically defined territories we turned into a more short-scale characteristic, one that we know too well from our previous works on promoter architectures in both yeasts and men: nucleosome positioning.
By obtaining publicly available nucleosome occupancy data we looked into the patterns of nucleosome positioning around the transcription start sites of the genes contained in each of the defined domains. Even though there is a general pattern of nucleosome positioning in yeast genes, with a clear nucleosome free-region (NFR) located exactly upstream of the TSS, we were surprised to see that different topological domains harboured genes with very different nucleosomal architectures. We were, moreover, able to cluster yeast TADs in six different categories, according to their patterns of nucleosome positioning. In the Figure below, one can see how radically different the short-scale chromatin structures can be. A clear distinction between a more "open" and a more "closed" chromatin conformation can be directly linked to regulatory and functional properties of these domains. The main point though, was that we were able to answer our initial question: There appear to be structurally-defined landmarks that distinguish different "neighbourhoods" in the yeast genome. Even though, a large number of additional aspects can be thought of (enrichment in transcription factors, epigenetic marks etc), nucleosome positioning patterns represent a more general characteristic that is directly linked (and possibly affecting) most others.
By obtaining publicly available nucleosome occupancy data we looked into the patterns of nucleosome positioning around the transcription start sites of the genes contained in each of the defined domains. Even though there is a general pattern of nucleosome positioning in yeast genes, with a clear nucleosome free-region (NFR) located exactly upstream of the TSS, we were surprised to see that different topological domains harboured genes with very different nucleosomal architectures. We were, moreover, able to cluster yeast TADs in six different categories, according to their patterns of nucleosome positioning. In the Figure below, one can see how radically different the short-scale chromatin structures can be. A clear distinction between a more "open" and a more "closed" chromatin conformation can be directly linked to regulatory and functional properties of these domains. The main point though, was that we were able to answer our initial question: There appear to be structurally-defined landmarks that distinguish different "neighbourhoods" in the yeast genome. Even though, a large number of additional aspects can be thought of (enrichment in transcription factors, epigenetic marks etc), nucleosome positioning patterns represent a more general characteristic that is directly linked (and possibly affecting) most others.
The results of this work were published in a recent paper by our group, in which, besides putting forward some interesting hypotheses on genome evolution (more on that soon), we are also proud to have "squeezed" a reference to one of our favourite books in the title.
 RSS Feed
RSS Feed
