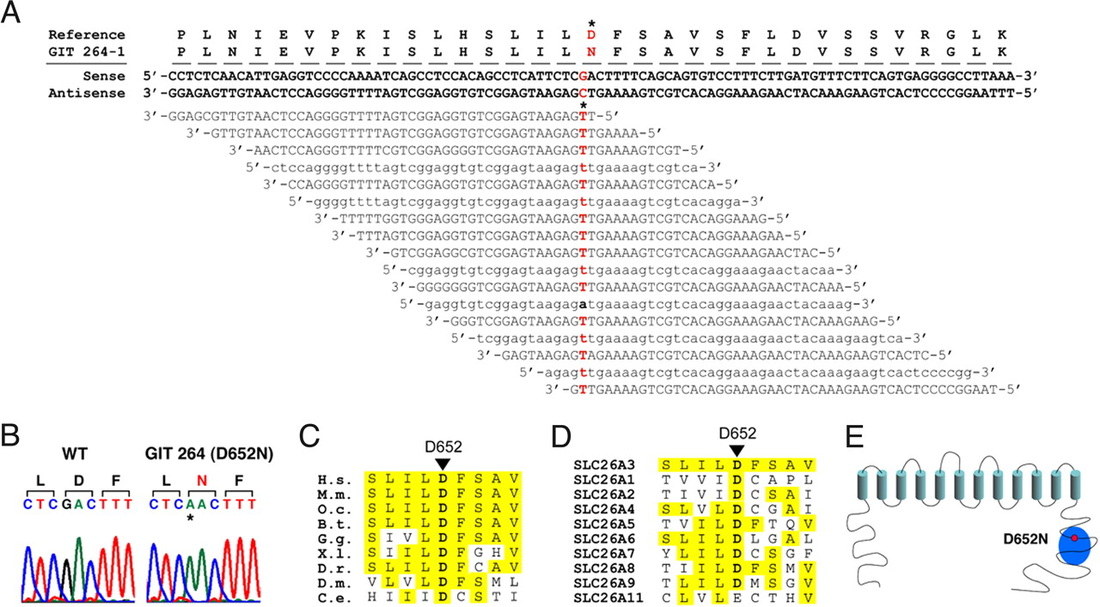
(image adapted from Choi et al., PNAS 2009)
A work published recently in the New England Journal of Medicine (Yang et al. Clinical whole-exome sequencing for the diagnosis of mendelian disorders. NEJM 2013) presents a summary of the findings of the application of Whole-Exome-Sequencing (WES) in a clinical setting.
The data used: Researchers and medical doctors at the Baylor College of Medicine followed the results of the application of WES in 250 consecutive cases in search for the cause of rare (or unidentified) genetic diseases. A total of 62 cases (~25%) were able to be diagnosed via this next-generation sequencing approach, a yield that is significantly higher than other conventional genetic tests (~15%).
The analysis: Analysis involved application of standard pipelines (quality control, mapping on the reference genome, calling of variants, functional analysis of variants after filtering for known SNPs). The results provided significant insight in the cause of various disease (most of which were related to neurological disorders associated to mental retardation). It is important to notice that not only the diagnostic yield was increased with the application of WES, but that even previously unknown gene-disease relationships were revealed through this approach. Moreover, the inquiry at a genome-wide scale led to the identification of incidental findings in almost half of the positive cases (30/62) something which would have not been possible through conventional methods. One particular case is quite representative of the potential of WES.
"For example, one patient (Patient 14 in Table S3 in the Supplementary Appendix) had whole-exomesequencing ordered at 26 months of age. He had previously been evaluated by means of chromosomal microarray analysis, DNA methylation, eight single-gene sequencing tests, mitochondrial genome sequencing by next-generation sequencing, respiratory-chain enzyme analysis, and multiple biochemical analyte studies. On the basis of the charges listed for these tests, we found that the cost of this patient’s previous genetic testing was three times as high as the current cost of whole-exome sequencing. This patient carried a mutation in SYNGAP1, which is associated with a newly recognized nonsyndromic mental retardation that may not have been identified by conventional genetic testing. He also had an incidental, medically actionable mutation in FBN1 that would have escaped detection without whole-exome sequencing."
Taking into account that as the cases analyzed with WES increase, we are bound to be able to associate more diseases with previously unidentified genetic causes, It becomes increasingly relevant to consider WES as the standard approach for genetic testing.
What's next: More exomes, faster and cheaper becoming routine practice in the clinic.
Read more: On whole exome sequencing (WES) and its applications in medical genetics in this report of the Baylor College of Medicine.
A work published recently in the New England Journal of Medicine (Yang et al. Clinical whole-exome sequencing for the diagnosis of mendelian disorders. NEJM 2013) presents a summary of the findings of the application of Whole-Exome-Sequencing (WES) in a clinical setting.
The data used: Researchers and medical doctors at the Baylor College of Medicine followed the results of the application of WES in 250 consecutive cases in search for the cause of rare (or unidentified) genetic diseases. A total of 62 cases (~25%) were able to be diagnosed via this next-generation sequencing approach, a yield that is significantly higher than other conventional genetic tests (~15%).
The analysis: Analysis involved application of standard pipelines (quality control, mapping on the reference genome, calling of variants, functional analysis of variants after filtering for known SNPs). The results provided significant insight in the cause of various disease (most of which were related to neurological disorders associated to mental retardation). It is important to notice that not only the diagnostic yield was increased with the application of WES, but that even previously unknown gene-disease relationships were revealed through this approach. Moreover, the inquiry at a genome-wide scale led to the identification of incidental findings in almost half of the positive cases (30/62) something which would have not been possible through conventional methods. One particular case is quite representative of the potential of WES.
"For example, one patient (Patient 14 in Table S3 in the Supplementary Appendix) had whole-exomesequencing ordered at 26 months of age. He had previously been evaluated by means of chromosomal microarray analysis, DNA methylation, eight single-gene sequencing tests, mitochondrial genome sequencing by next-generation sequencing, respiratory-chain enzyme analysis, and multiple biochemical analyte studies. On the basis of the charges listed for these tests, we found that the cost of this patient’s previous genetic testing was three times as high as the current cost of whole-exome sequencing. This patient carried a mutation in SYNGAP1, which is associated with a newly recognized nonsyndromic mental retardation that may not have been identified by conventional genetic testing. He also had an incidental, medically actionable mutation in FBN1 that would have escaped detection without whole-exome sequencing."
Taking into account that as the cases analyzed with WES increase, we are bound to be able to associate more diseases with previously unidentified genetic causes, It becomes increasingly relevant to consider WES as the standard approach for genetic testing.
What's next: More exomes, faster and cheaper becoming routine practice in the clinic.
Read more: On whole exome sequencing (WES) and its applications in medical genetics in this report of the Baylor College of Medicine.
 RSS Feed
RSS Feed
